How to infer skills from unstructured content - emerging best practices


Steven Forth is co-founder and managing partner at Ibbaka. See his skill profile here.
There are many reasons to infer skills from unstructured content. It is one way to seed skill profiles and to keep them current. It is also used in future skills research and in skill-based strategies, where finding skill differentiation is critical. Before we get to the how, let’s look at the what and the why. After we look at the how, we will consider some of the ethical and operational issues.
Why infer skills from unstructured content
There are many approaches to understanding what skills we have, who we use them with and how we put them to work. One can take courses and tests, fill out surveys, or (and I think this is the best way) simply have a series of conversations. Why then go to the trouble of building a skill extraction system?
At Ibbaka we have invested a great deal into this technology and we use it in three main ways.
As a way to seed skill profiles and to keep them current
To give insights into future skill requirements
For comparisons of skill differentiation
As a way to seed skill profiles and to keep them current
This is the most common use case. Most people do not want to take the time to populate their skill profile or to keep it current. And many of us find it difficult to articulate what our skills are. One way to get started is to simply upload a set of files and let an AI figure out what skills are demonstrated. All sorts of documents are relevant for this.
Résumés and C.V.s
Profiles on public sites such as LinkedIn
Project Reports and other work products
Project descriptions and requirements documents
Patent filings
Blog posts
Emails
Chat in collaboration sites like Slack or MS Teams
The basic idea here is that the best way to understand a person’s skills is to look at their work. What are they asked to do? What are the outputs? How do they go about helping others? (An advanced technique is to look at email and chat and see who gets asked for help and what help they provide.) One takes a representative set of documents, runs them through a skill extraction and inference system, and gets a list of skills, often with estimates of the level of expertise.
Skill profiles can change quite quickly in today’s world, as people are faced with new challenges and opportunities and agile learning has become the norm. This makes it difficult to keep skill records current. Providing a regular feed of content can automate this process, leading to more accurate and current skill profiles. This can even lead people to pay more attention to their own and other’s skill profiles as watching skills change over time is more interesting than looking at a static view.
Insights into future skill requirements
Many organizations are concerned with what skills they will need in the future. This is a fascinating area to play, Ibbaka has done studies on this in a number of sectors. One input into such work is skill extraction from documents that are thought to reflect future directions. Patent filings are one place to look. It can take as long as twenty years for a new technology to percolate into the workplace, and patents can be a good leading indicator. Looking at adjacent industries can also provide context (Michael Porter’s frameworks are still helpful in this context), as can tracking the emerging skills of disruptive young companies. University research papers can also, in certain cases, give insights into possible future skills.
Skill inference is just one input into future skills research, and it requires context from things like scenario planning (and the identification of critical uncertainties) and foresight.
Skill differentiation
Differentiation is key to strategy and competitive positioning. There are a set of common skills (sometimes called core skills) that all people may need at some level (numeracy, literacy, critical thinking, generative thinking, visual thinking and so on), and there are skills common for different functions and in different domains. These are generally best represented in a skill and competency model (see the posts below for some of Ibbaka’s work in this area). Just as important though, are the skills that differentiate us from one and other, that express our originality. For some of us it is more difficult to articulate our differentiating skills and skill inference can be of real help here.
Ibbaka also uses skill inference to compare companies and get insights into their strategies. This often takes the form of identifying a small group of companies (generally no more than five) that compete with each other and then scraping their websites and published content for skill data. A graph is built in which each skill is a node and there are N types of edges connecting the skills (N being the number of companies). Standard graph analysis procedures are then used to understand the similarities and differences between the companies.
This is just one input into skill differentiation analysis of course. One also looks at other strategic indicators, product and service offerings, interviews customers and so on to get a holistic view. Once one has an understanding of the skill differentiation of the different participants one can begin to understand the strategic moves available in the industry.
Limitations to the skill extraction approach
Skill extraction and inference is not a silver bullet. It will not solve all of the challenges of skill management and needs to be used in concert with other approaches, such as social interactions, formal skill surveys, skill interviews for key staff and the injection of competency models.
The most important limitations of skill extraction and inference are given below.
Not relevant for all types of work
There are many jobs that do not generate the types of documents needed for skill extraction and inference. Only jobs that lead to the creation of written documents are really tractable with this approach. Even within the same job type, different approaches to work may lead to one person to generate many documents while another person may get similar results through meetings and conversations.
Excessive reliance on skill extraction and inference can bias the organization to jobs that manifest themselves in written documents, and under represent the skills of other people. This can negatively impact diversity and inclusion.
Will not always find tacit skills and knowledge
People with a background in knowledge management will be aware of the idea of ‘tacit knowledge.’
Tacit knowledge or implicit knowledge—as opposed to formal, codified or explicit knowledge—is knowledge that is difficult to express or extract, and thus more difficult to transfer to others by means of writing it down or verbalizing it. This can include personal wisdom, experience, insight, and intuition.
For a wider discussion of tacit vs. explicit knowledge see this course from Tallinn University.
In most cases, skill extraction and inference will not do a good job of identifying tacit knowledge and other techniques will be needed to fill this out and get a more complete picture of skills.
Will skew to knowledge aspect of Knowledge skills and attributes
One of the key constructs inskill management is that of KSA for Knowledge, Skills and Attributes (see The A in KSA is for Abilities or Attitudes or Attributes?). Skill extraction techniques tend to be best at picking out knowledge, spotty and unpredictable when it comes to skills and poor at identifying attitudes.
Over reliance on knowledge over skills and attitudes feeds into the syndrome in which the most verbal people are seen as the most qualified and capable. Other ways to approach work, which may be even more important, are overlooked.
There is no one way to identify or assess skills or knowledge that work for all jobs, working styles or cultures. Excessive reliance on skill extraction and inference will have a negative impact on diversity and inclusion.
Can lead to misattributions in the case of teams
With more and more work being done by teams, skill management systems need to be good at showing how the different people on a team have contributed to the work. In most cases, this is difficult to do with skill extraction and inference. Integration with project management systems is a better path forward for people interested in this. It may be that ‘listening’ on communications and collaboration software (email, Slack, MS Teams) will also be a path towards this.
How to infer skills from unstructured content
The basic components of a skill identification platform are straightforward. One needs to be able to index the source documents, extract entities, map to a skill graph and run inference systems to enrich the skills discovered with skills that may be present but are not specifically mentioned. A simple sketch is provided below.

Let’s look briefly at each of these.
Indexing
Content indexing is a mature technology and there are many tools available to do this across many content types. Any content that uses words (including the spoken word such as videos and podcasts) can be indexed using existing technology. There are many open source options available as well. Research in the field continues, with some of the most most exciting work based on Bayesian networks (the same technology that underlies neural networks and deep learning). The index is the raw material on which skill extraction works.
Concept extraction
Concept extraction is also a relatively mature technology. It takes the terms indexed and organizes them in some form of taxonomy or more recently ontology (an ontology is a more general approach that covers the representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities that substantiate). Most advanced skill extraction systems pass through a general concept mapping before reducing the data to a set of connected skills.
The skill graph
The skill graph is a set of connected skills, generally represented in RDF or as a Bayesian network. The basic structure of a typical skill graph is shown below. The skill graph is the underlying data model for skill management and the most important part of a skill management system. Building, populating and connecting the skill graph is the technical goal of skill extraction and skill inference.
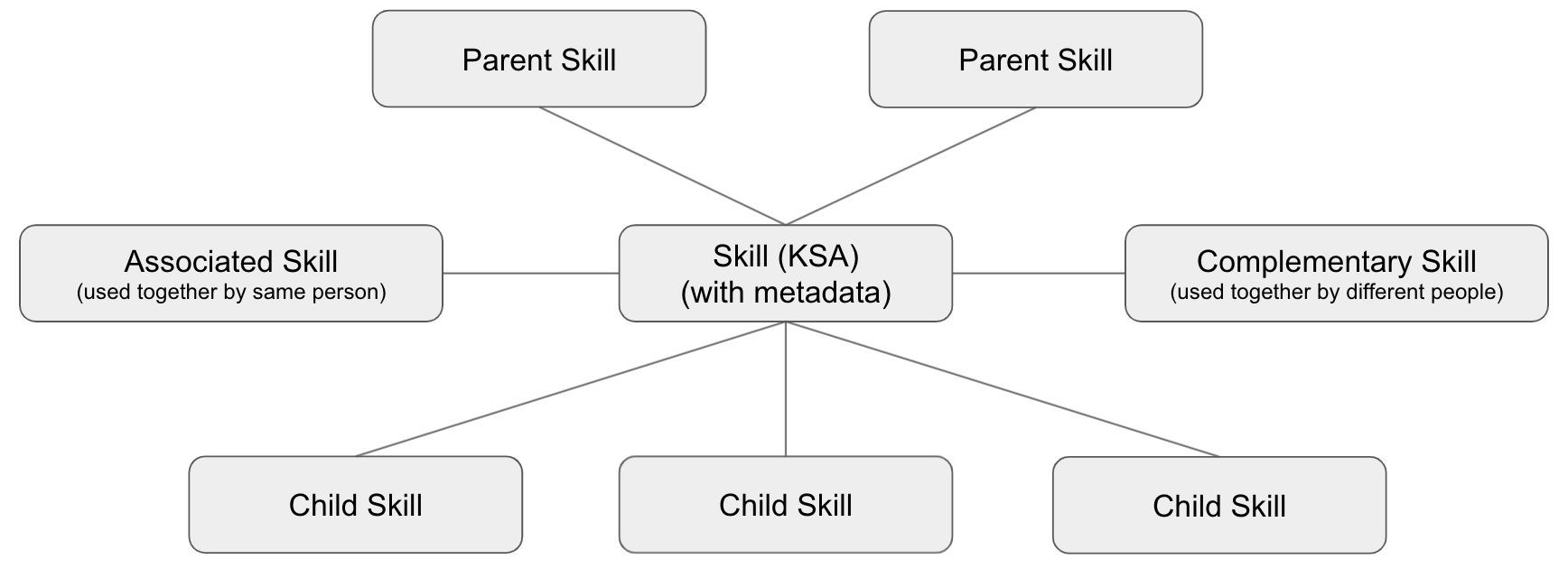
The skills terms identified by skill extraction and inference are inserted into the skill graph and may change weights in the Bayesian network.
The extended skill graph, which is what we use at Ibbaka, connects skills to Jobs, Roles, Projects, Goals and other constructs critical to understanding and supporting potential and performance.

Skill graph mapping
Mapping concepts to skills is a key step in skill extraction and inference. It moves us from the generic world of concepts and entities to the more specific world of skills and performance.
Without this step, skill graphs become cluttered with general concepts and lose fidelity.
Skill inference
The final step in skill extraction and inference is to take the skills explicitly identified and infer additional skills. This is done in two ways: through parent child relationships and through associated skills.
If a person has a certain pattern of child skills one can infer a parent skill. If a person has two or more of the parent skills, one can infer the child skills.
Associated skills are simplers. These are simply the skills that experience shows (as captured i the skill graph) are likely to be found together in the same person.
These inferences are probabilistic, Ibbaka takes a Bayesian approach estimating the a priori probability of an inference and then adjusting this based on the evidence.
Skills should not be forced into an individual’s skill profile. For more on this, see the next section.
How to manage the skills extracted and use them in skill profiles
Skill extraction and inference is a powerful tool. It is a good way to quickly survey some of the skills in an organization and to seed skill profiles. It can enrich the skill graph in valuable ways. But it has serious limitations. The skills extracted should not be inserted into a person’s skill profile without their permission. Indeed, this is a general design rule at Ibbaka.
Do not add a skill to an individual skill profile without the person’s permission.
There are many reasons for this. The AI may have made a mistake and the person may not feel that they have the skill in question. In some case, they may have the skill but do not wish to apply it in the context of their job (in this case we suggest accepting the skill but then hiding it). People will only trust the system if they have control over their own profile.
As noted, there are many skills, roles or approaches to work where the skill will not show up in documents. A good skill management systems needs to provide several different ways for skills to enter a person’s profile.
Provide multiple paths for skills to enter a skill profile.
Generally speaking, we want to know not only if a person has a skill but the level of expertise. Skill extraction alone is a poor way to do this.
Seek different forms of evidence for the level of expertise.
Skill management is syncretic in nature. It requires the integration of many different approaches to give a holistic view of a person’s current skills, how these skills are being applied and their potential to develop and apply new skills. It needs to address the individual, team and organizational levels simultaneously. Most importantly, it must give people agency, they must be in control of what skills show up in their profile.
Skill extraction from content is an important part of this, but can by no means be the whole story.
Ibbaka posts on competency models and competency frameworks
How to infer skills from unstructured content - emerging best practices (this post)
From user experience to competency model design - Margherita Bacigalupo and EntreComp
Competency framework designers on competency framework design: The chunkers and the slice and dicers
Competency framework designers on competency framework design: Victoria Pazukha
Design research - How do people approach the design of skill and competency models?
The Skills for Career Mobility - Interview with Dennis Green
Lessons Learned Launching and Scaling Capability Management Programs
Talent Transformation - A Conversation with Eric Shepherd, Martin Belton and Steven Forth
Individual - Team - Organizational use cases for skill and competency management
Co-creation of Competency Models for Customer Success and Pricing Excellence
Competencies for Adaptation to Climate Change – An Interview with Dr. Robin Cox
Architecting the Competencies for Adaptation to Climate Change Open Competency Model
Integrating Skills and Competencies in the Talent Management Ecosystem
Organizational values and competency models – survey results







